


- 0.3–0.5s E2E, impossible for cloud
- One-time hardware, no per-call fees
- Rock-steady — network stays stable

- Major languages, zero config needed
- Machine, Simulated, or Human voice
- Clone any voice with ~10s of audio

- Text-only upload reduces cloud costs
- Voice stays on-device, fully private
- No cloud: region, rate, or shutdown
- Works offline or on weak networks

Multi-lang ASR · Interpreting · Natural TTS
On-device multi-lang recognition, real-time translation & natural TTS. Deploy on desktop, meeting terminals, guide kiosks for two-way dialogue & cross-language communication.
Core Advantages
- Multilingual Recognition: Major languages ready out of the box
- Simultaneous Interpretation: Listen-and-translate w/ 0.3–0.5s E2E latency
- Tiered Voice Quality: Machine / Simulated / Human — pick by budget




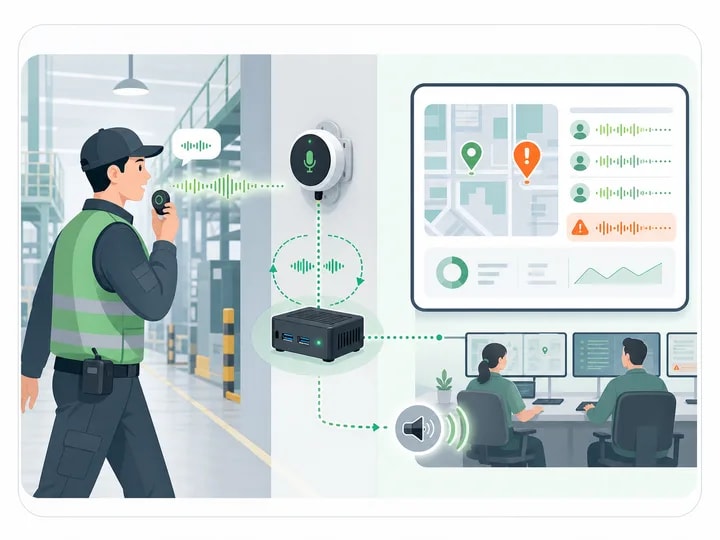
Voice device control & field data entry
Voice replaces UIs & scanners in warehouses & workshops. Workers use natural language for logging, inspection, patrol forms & alerts. Local ASR outputs structured text for WMS, MES & IoT.
Core Advantages
- Lower Op Barrier: Natural language replaces UIs, scanners & work-order apps
- Weak-Network Ready: Local ASR w/ text backhaul — independent of on-site bandwidth
- Structured Output: Results feed directly into WMS, MES & work-order systems



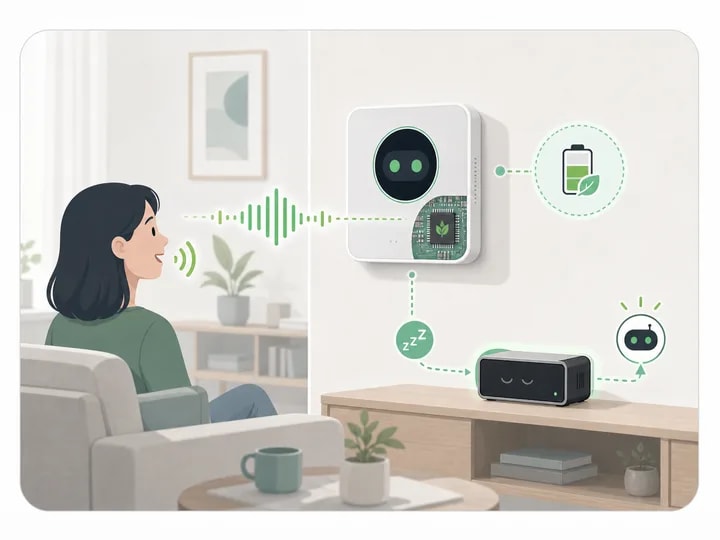
Instant Wake · Local Control · Voiceprint
XIAO ESP32S3 low-power wake frontend triggers ASR-TTS on AI box. Voiceprint ID for per-member preferences. Integrates w/ Matter, HomeAssistant, Mi Home. Fully local — offline won't disrupt use.
Core Advantages
- Milliamp-Class Wake Frontend: ESP32S3 ESP-SR always-on, lasting months on battery
- Voiceprint: Identify members & load personal preferences
- Local Control: Integrated w/ Matter, HomeAssistant, Mi Home & more
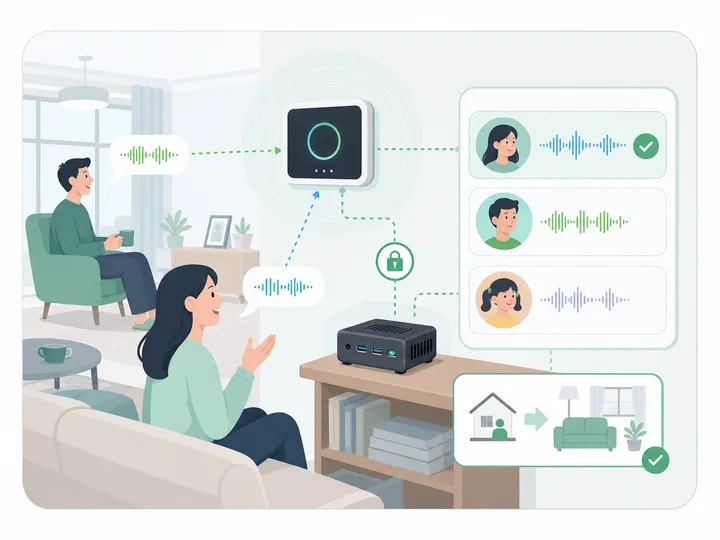
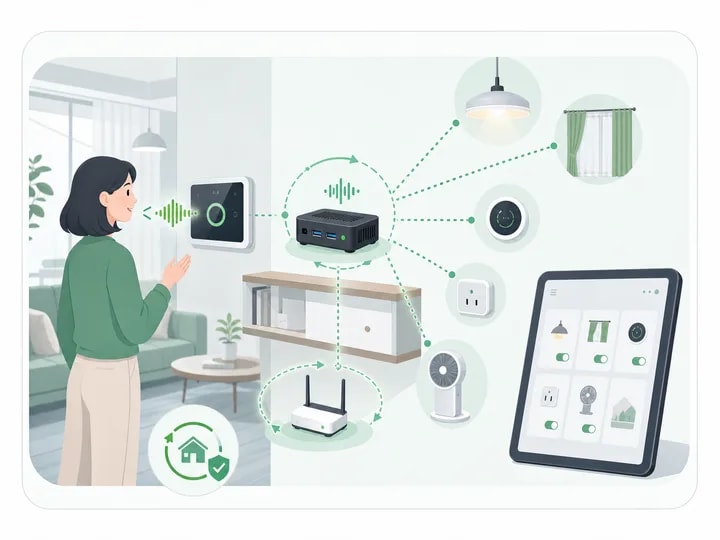
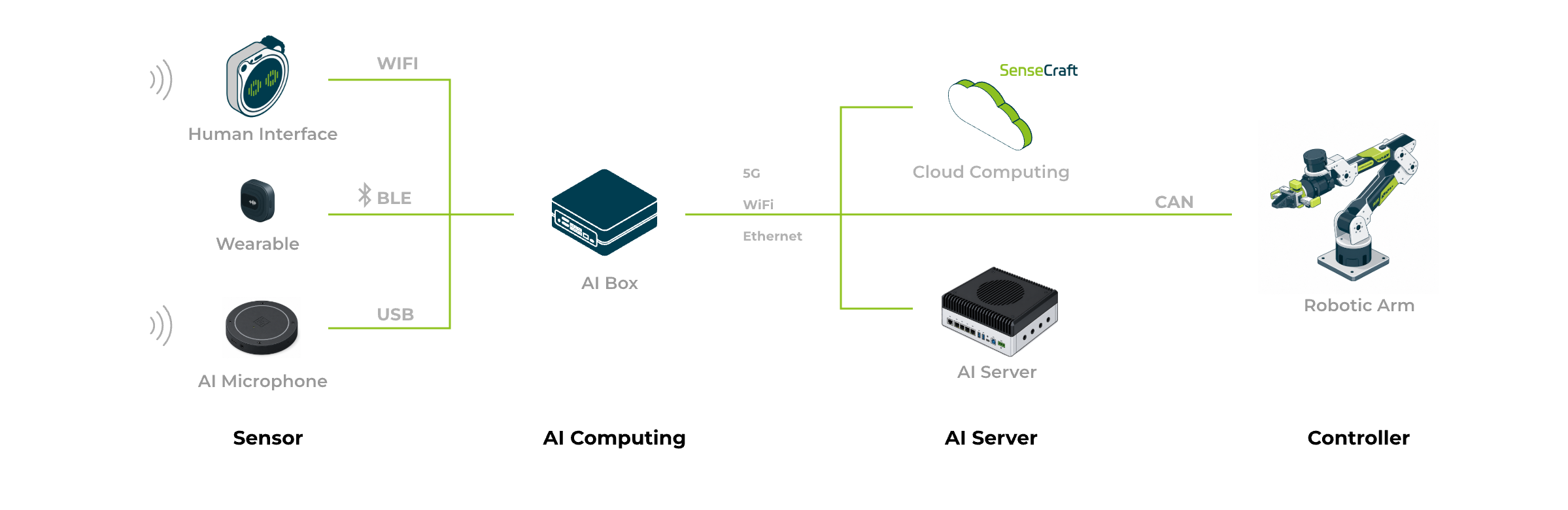
Three Models: Frontend, Hybrid, All-in-One
Voice compute placement determines capability ceiling & per-unit BOM. Three common models:
Core Advantages
- Frontend (ESP32S3): Low-power wake & simple commands; pair w/ your host system
- Hybrid (Frontend + Box): Edge wakes + ASR + TTS; LLM remote. Best value.
- All-in-One (High-End): Single Jetson, full ASR/TTS/LLM. Privacy & offline.
| Product | Tier | Accuracy | Voice Capabilities | Concurrency | Demo Voice | Price |
|---|---|---|---|---|---|---|
 XIAO ESP32-S3 Sense XIAO ESP32-S3 Sense | Wake Frontend | — | Wake Word / Command | — | — | ~$10 |
 reRouter CM4 reRouter CM4 | Entry | Basic | Single-lang ASR | — | Machine | $200–300 |
 reComputer AI R2130-12 reComputer AI R2130-12 | Entry | Medium | Single-lang Dialogue | Single | Simulated | ~$339 |
 reComputer RK3576 reComputer RK3576 | Standalone | Good | Multilingual Dialogue + Local LLM* | Single | Simulated | ~$139 |
 reComputer RK3588 reComputer RK3588 | Standalone | Good | Multilingual Dialogue + Local LLM* | Single | Simulated | ~$199 |
 reComputer J3011 reComputer J3011 | Professional | Good | Multilingual Dialogue | 2 ch | Simulated / Natural | ~$599 |
 reComputer J4012 reComputer J4012 | Professional | Good | Multilingual Dialogue + Local LLM | 2–3 ch | Simulated / Natural | $800–900 |
 reComputer J5012 reComputer J5012 | Flagship | Excellent | Multilingual Dialogue + Advanced LLM | High | Natural | ~$2,000 |
Choose AI Compute Box by Capability
Compute boxes tiered by voice capabilities. The table lists tier, accuracy, capabilities, concurrency, voice quality & price. (See next tab for mic & speaker selection.) *Local LLM on the RK series requires the 1282 AI accelerator add-on card.
Core Advantages
- Wake & Commands → Wake frontend, ~$10 all-in-one
- Best-value standalone → RK series: multilingual dialogue + local LLM, single-channel, simulated voice
- Pro-tier natural voice → J series: J3011 offers human-like voice & 2 concurrent channels; J4012 adds local LLM & 2–3 channels
- High concurrency + advanced LLM → J5012 flagship, full pipeline on one device
| Product | Type | Chip | Pickup Range | Coverage Angle | Built-in Amp | Core Algorithms |
|---|---|---|---|---|---|---|
 reSpeaker Lite reSpeaker Lite | Linear 2-Mic | XMOS XU316 | 3m | 180° | 5W | AEC · DoA |
 reSpeaker XVF3800 reSpeaker XVF3800 | Circular 4-Mic | XMOS XVF3800 | 5m | 360° | 5W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Circular-4 reSpeaker Flex Circular-4 | Circular 4-Mic | XMOS XVF3800 | 5m | 360° | 10W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Linear-4 reSpeaker Flex Linear-4 | Linear 4-Mic | XMOS XVF3800 | 5m | 180° | 10W | AEC · DoA · Multi-beamforming |
Three Core Advantages of the reSpeaker Series
Core Advantages
- ① Superior Hardware Audio Pickup Hardware architecture purpose-built for embedded scenarios physically isolates noise interference. Combined with array layout for DOA sound-source localization, pickup performance is notably ahead of comparable products.
- ② On-Board AI Acoustic Algorithms XMOS chip runs AEC echo cancellation, noise reduction, and beamforming on-board in real time. Clean audio is output directly from the frontend, reducing recognition errors at the backend.
- ③ Open Ecosystem Firmware and SDK are open to developers, enabling independent parameter tuning without relying on Seeed for secondary development. Compatible with XIAO ESP32S3, Raspberry Pi, Jetson, and all USB / I²S platforms for flexible integration.